Di truyền học Sóng-Ngôn ngữ: hướng đi mới của di truyền học (Phần 2)
Theo lý thuyết kết cặp bazơ linh hoạt của Francis Crick – nhà bác học đoạt giải Nobel nhờ khám phá ra cấu trúc DNA – có 8 mã trong tổng số 64 mã di truyền của con người có thể gây ra các sai sót nghiêm trọng trong quá trình tế bào tổng hợp protein, với xác suất lên tới 6,25%. Nếu điều này diễn ra trong thực tế thì quá trình sinh trưởng của loài người có thể sẽ gặp những vấn đề nghiêm trọng về di truyền.
Tiếp theo Phần 1
Quá trình phiên mã và dịch mã để tổng hợp protein
Sau khi khám phá ra cấu trúc xoắn kép của DNA (đoạt giải Nobel 1962), 2 nhà khoa học Francis Crick (1916-2004) và James Watson (1928-2003) đã đề xuất ba kiểu truyền thông tin di truyền có thể có trong các tế bào: (1) Tái bản (replication): DNA → DNA; (2) Phiên mã (transcription) DNA → RNA; và (3) Dịch mã (translation): RNA → Protein. Các kênh truyền thông tin này còn được gọi là giáo lý trung tâm (central dogma) của sinh học phân tử. Sau này đến năm 1970, Baltimore và Temin trên cơ sở nghiên cứu cơ chế hoạt động của bộ gen RNA ở virus Sarcoma đã bổ sung thêm kênh RNA → DNA, gọi là Phiên mã ngược (reverse transcription) [1].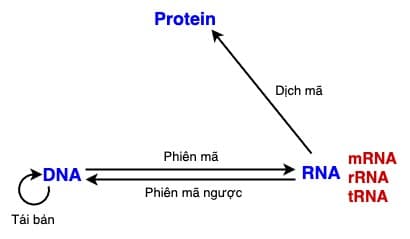
Phần lớn các sinh vật tế bào sử dụng các RNA để truyền đạt các thông tin truyền từ bộ gen (DNA) đến các protein qua quá trình phiên mã và dịch mã. Các thông tin di truyền được sử dụng là các phân tử bazơ nitơ hay còn gọi là nucleobase.
DNA chứa bốn loại phân tử bazơ nitơ chính (còn gọi là nucleobase hay base) là adenine (A), guanine (G), thymine (T) và cytosine (C), các bazơ này nằm trong các phân tử nucleotide (gồm 1 phân tử base nitơ, 1 phân tử đường và 1 phân tử gốc phốt phát) chạy dọc theo mạch xoắn của DNA. Trong RNA cũng chứa các bazơ như thế, chỉ khác là uracil (U) thay thế thymine (T).
Trong quá trình phiên mã (transcription), ban đầu DNA được cuộn xoắn. Khi có tín hiệu phiên mã, một đoạn DNA được tháo xoắn (unwind). Một mạch DNA đã được tháo xoắn được sử dụng làm mạch gốc (hay mạch khuôn). Enzym RNA polimeraza sẽ vừa di chuyển theo mạch gốc vừa lắp các ribonucleotit tự do vào mạch theo nguyên tắc bổ sung ADNA-gốc – URNA, GDNA-gốc – CRNA, TDNA-gốc – ARNA, CDNA-gốc – GRNA tạo thành phân tử RNA. Khi enzym di chuyển đến cuối mạch gốc, gặp tín hiệu kết thúc phiên mã, phân tử RNA sẽ được giải phóng, đoạn mạch DNA đã tháo xoắn lại được hồi phục về trạng thái xoắn kép như cũ.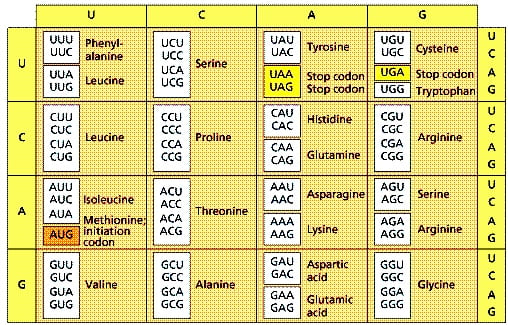
Trong quá trình dịch mã (translation), RNA thông tin mRNA (messenger RNA) mang các thông tin di truyền về trình tự của một protein đến ribosome, nhà máy tổng hợp protein bên trong tế bào. Nó mã hóa sao cho cứ mỗi 3 phân tử bazơ (bộ 3 mã hóa – triplet code) gọi là một codon trên mRNA tương ứng với 1 axit amin.
Tại ribosome, RNA vận chuyển tRNA (transfer RNA) vận chuyển một loại axit amin nhất định đến gắn vào chuỗi polypeptide (chuỗi axit amin ngắn sắp xếp theo một trật tự nhất định) đang dài dần ra. Loại axit amin được tRNA mang đến cũng được quy định bởi mã bộ 3 phân tử bazơ nitơ của nó gọi là đối mã (anticodon). Đối mã anticodon trên tRNA này cần phải khớp bổ sung với mã codon của mRNA theo cặp A-U, G-C, U-A, C-G nhưng đảo vị trí: vị trí thứ nhất của anticodon khớp với vị trí thứ 3 của codon, vị trí thứ 2 của anticodon khớp với vị trí thứ 2 của codon, vị trí thứ 3 của anticodon khớp với vị trí thứ nhất của codon.
Sau khi axit amin mới được liên kết với các axit amin đã có trên chuỗi polypeptide, tRNA rời đi, ribosome dịch chuyển đi một mã bộ 3 trên mRNA, một tRNA khác mang axit amin khác có anticodon khớp với codon của mRNA hiện tại tại vị trí ribosome đang tổng hợp rồi rời đi… Cứ như vậy, protein được tổng hợp như thế.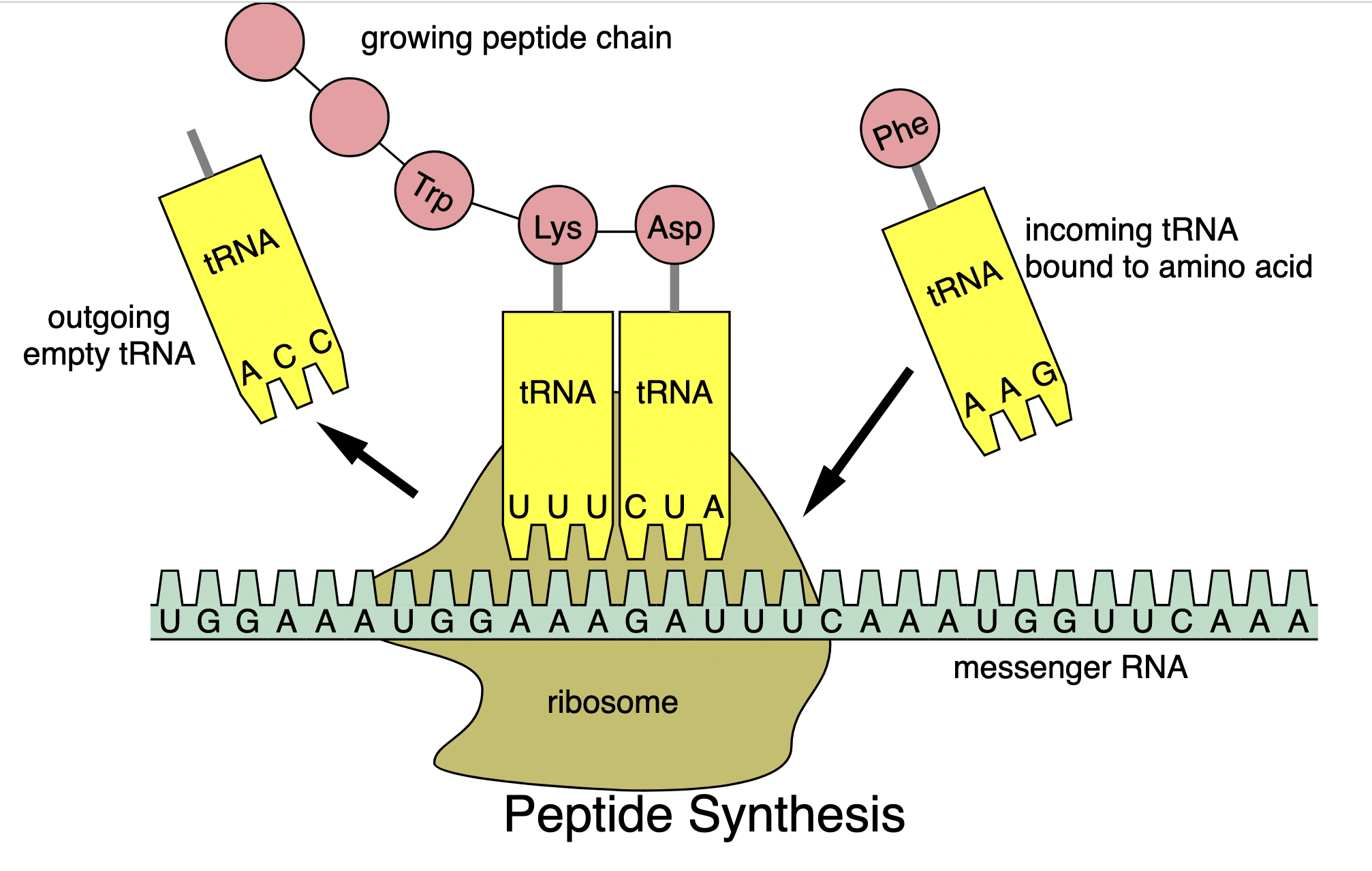
Sự “linh hoạt” trong việc kết cặp anticodon-codon
Ta đã biết, gen (DNA) được cấu tạo từ bốn loại phân tử bazơ nitơ, trong khi đó protein được cấu tạo bởi 20 loại axit amin. Vậy, các gen mã hóa cho các sản phẩm protein của chúng bằng cách nào?
Như đã trình bày, mã di truyền là mã bộ ba (triplet code) gồm 3 phân tử bazơ nitơ. Các mã bộ ba anticodon của tRNA có thể khớp với mã bộ ba codon của mRNA theo nguyên tắc bổ sung để xác định loại axit amin nào sẽ được tạo ra trong quá trình dịch mã.
Tổng cộng có 43=64 mã codon, nhưng được xác định là chỉ có 61 mã được cho là có ý nghĩa, trong khi chỉ có 20 loại axit amin. Vì vậy mỗi axit amin có thể được xác định bởi nhiều hơn một codon.
Các codon cùng xác định một axit amin như thế gọi là các codon đồng nghĩa; chúng thường khác nhau ở bazơ cuối (vị trí thứ 3) và bazơ đó được gọi là bazơ thoái hóa. Ví dụ, các axit amin Arg, Ser và Leu mỗi cái có tới sáu codon đồng nghĩa
Năm 1966, Francis Crick đưa ra một cách để giải thích về sự kết cặp “lỏng lẻo” có thể xảy ra ở vị trí thứ ba của các codon đồng nghĩa. Theo Crick, hai bazơ đầu tiên của một codon phải có sự kết cặp chính xác với anticodon (theo nguyên tắc bổ sung), còn bazơ cuối của codon thì có thể “linh hoạt” (wobble), ít đặc thù hơn so với vị trí bình thường của nó để hình thành nên sự kết cặp bazơ bất thường với anticodon. Đề nghị này được gọi là giả thuyết linh hoạt (wobble hypothesis). [2]
Francis Crick gợi ý rằng một bazơ G trong anticodon có thể cặp không chỉ với C ở vị trí thứ ba của một codon (vị trí linh hoạt), mà còn với U. [2]
Hơn nữa, ông Crick còn lưu ý một trong số các bazơ bất thường có thể có mặt trong tRNA là inosine (I). Một anticodon có I ở vị trí thứ nhất về tiềm năng có thể cặp với 3 codon khác nhau có bazơ cuối là C, U hoặc A. Các khả năng kết cặp bazơ “linh hoạt” được tổng hợp ở Bảng 2.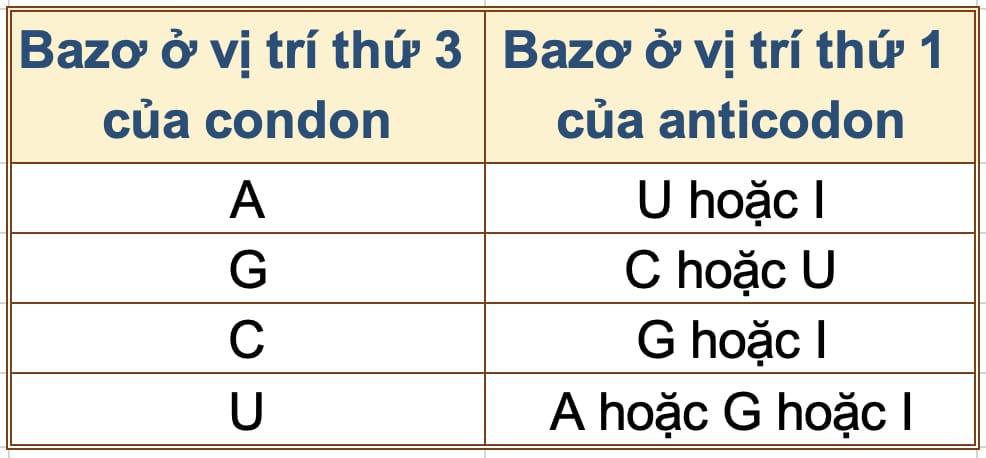
Các sai sót di truyền có thể xuất hiện bởi nguyên tắc kết cặp “linh hoạt”
Giả thuyết kết cặp linh hoạt (wobble hypothesis) của Francis Crick có thể dẫn đến các sai sót nghiêm trọng trong quá trình tế bào tổng hợp các axit amin dựa trên các thông tin trong quá trình dịch mã.
Ví dụ, nếu mRNA mang mã codon AUG tương ứng với axit amin loại methionine (viết tắt là Met) hoặc mã khởi đầu (Start) tùy hoàn cảnh mã AUG xuất hiện, thì anticodon do tRNA mang đến ribosome có thể là UAC – tương ứng với acid loại methionine (Met) hoặc mã khởi đầu (Start), hoặc cũng có thể là UAU – tương ứng với loại axit amin Isoleucine (Ile).
Tương tự nếu mRNA mang mã codon UGG tương ứng với acid tryptophan (viết tắt là Trp), thì anticodon trên tRNA có thể là AAC – tương ứng với acid tryptophan, hoặc ACU – tương ứng mã anticodon kết thúc (stop anticodon).
Báo cáo của Đại học Barcelona năm 2003 cũng xác định 1 mã condon trên mRNA có thể ghép với 2 mã anticodon khác nhau với sự xuất hiện của bazơ inosine (I) ở vị trí thứ nhất. Ví dụ, anticodon AAI có thể ghép đối mã với cả codon UUA (Leu) hoặc UUC (Phe), hay anticodon ACI có thể ghép đối mã với cả codon UGA (Stop) hoặc UGC (Cys). [3]
Như vậy, theo lý thuyết kết cặp bazơ linh hoạt (wobble hypothesis) của Francis Crick (nhà bác học đoạt giải Nobel nhờ khám phá ra cấu trúc DNA), khả năng xuất hiện sai sót trong quá trình di truyền là rất lớn, với xác suất lên đến (8/64)/2 = 6,25%.
Nếu điều này diễn ra trong thực tế thì chắc chắn quá trình sinh sản, phát triển của loài người sẽ không thể diễn ra một cách suôn sẻ và bình thường như chúng ta nhìn thấy. Đó sẽ là một “thảm họa” về di truyền.
Vậy vì sao con người vẫn được sinh trưởng gần như hoàn hảo với quá trình di truyền diễn ra một cách chính xác? Mời quý độc giả đón xem ở Phần 3 của bài viết.
Thiện Tâm
Quay lại Phần 1
Xem tiếp Phần 3, Phần 4, Phần 5
Tài liệu tham khảo:
[1] Giáo trình Nucleic Acid, Chương 5 – Sinh tổng hợp Nucleotide và DNA, trang 135; Hoàng Trọng Phán, Đỗ Quý Hải, NXB Đại học Huế
[2] Giáo trình Nucleic Acid, Chương 6 – Sinh tổng hợp RNA và Protein, trang 135; Hoàng Trọng Phán, Đỗ Quý Hải, NXB Đại học Huế
[3] Genome Variability and Capsid Structural Constraints of Hepatitis A Virus; Glòria Sánchez, Albert Bosch,* and Rosa M. Pintó
Xem thêm:
Xem thêm

Từ khóa DNA Di truyền học Dữ liệu di truyền di truyền học sóng-ngôn ngữ